Letting coding agents take over meaningful, large software projects sounds fascinating. The pitch is everywhere: give agents docs on what you want to build, let them branch, implement, fix, and hand back working software. On social media, the claims are easy to find. The operational details are shared less often.
We were especially inspired by OpenAI’s Symphony, which frames Linear issues as a control plane where each task can be assigned to an agent and humans review the result. That is the right direction. At the same time, our day-to-day workflow was still very direct: engineers were talking to Claude Code and Codex, shaping tasks, inspecting patches, and deciding when a change was ready.
So we kept the direct coding-agent loop, then moved classic code review into an agent-carried workflow.
That is why we built Crosscheck: an open-source assistant workflow that watches pull requests, runs an independent AI review, applies targeted fixes when configured, re-checks the result, and keeps pushing the PR toward a mergeable form when the automated path is safe. The preferred pattern is cross-vendor: let one setup create or fix, then let another setup review so the workflow catches blind spots that a single vendor loop may miss.
Crosscheck is open source. Install @humanbased/crosscheck from npm, connect GitHub plus Codex or Claude Code, and run review loops from your own machine or server.
The product choice is deliberately pragmatic. Crosscheck drives Codex and Claude Code directly for review, fix, re-check, and conflict-resolution steps. That gives us two useful properties. First, Claude Code and Codex can work in sequence and help each other: one agent creates or fixes, another reviews, and the loop exposes blind spots. Second, teams can keep using the coding-agent subscriptions they already pay for instead of converting every review loop into a new per-token API bill.
This analysis asks a practical question: which workflow choices protect quality without slowing the team down?
The short version:
- Keep PRs shaped around one coherent review unit. A 2-3 ticket bundle can be fine when it is one domain and one acceptance story; 4+ ticket PRs should be split or escalated by default.
- Route review strength from demand complexity plus PR shape. Do not wait for long review loops to tell you the workflow was expensive.
- Use smaller/faster reviewer models by default, then escalate when risk signals appear. The current data is good enough for routing policy, not good enough to rank coding agents.
- Make Crosscheck a measurement system as much as a review runner. Provenance, original-vs-fixed state, and post-merge quality joins are the missing pieces.
What we analyzed
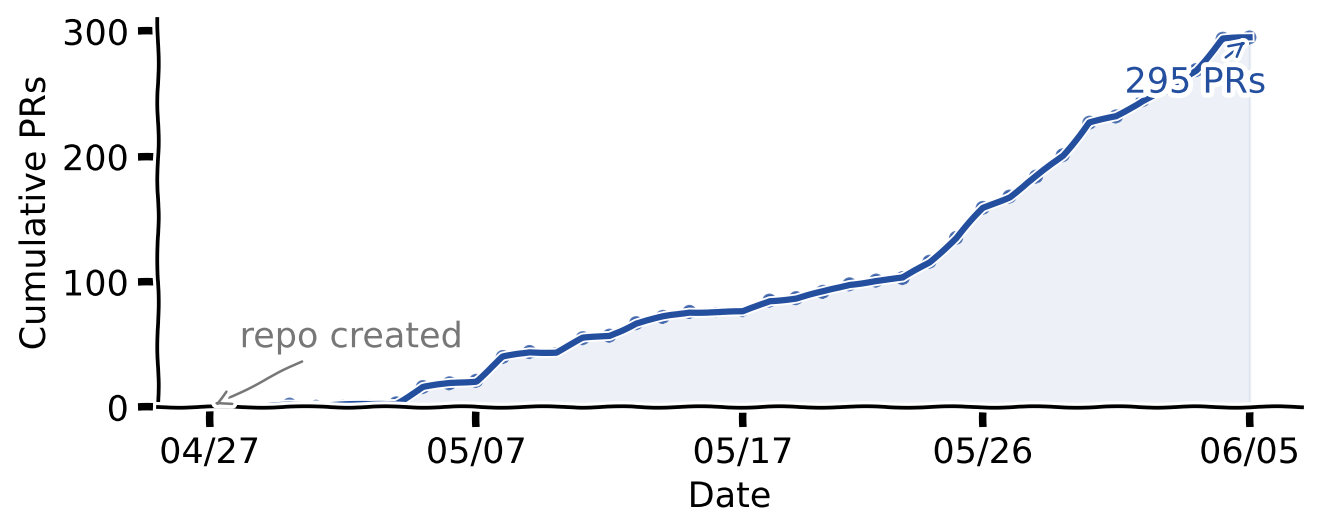
We joined GitHub PR metadata for humanbased-ai/monorepo with retained local Crosscheck logs. The repository was created on 2026-04-27T10:08:41Z; the first PR in the dataset was opened on April 30; the analysis window runs through June 5, 2026.
The full PR population covers 295 pull requests. The retained Crosscheck logs cover May 24 to June 5, giving us a smaller workflow-observed subset of 96 PRs.
The core measurements:
| Measure | Value |
|---|---|
| PRs since repo creation | 295 |
| Non-doc PRs | 286 |
| PRs in retained Crosscheck logs | 96 |
| Recorded workflow minutes | 2,948.8 |
| Recorded review hours | 49.1 |
| 24-hour days of workflow | 2.0 |
| Unique ticket refs | 157 |
We separate the goal from the implementation:
- Problem complexity is derived from issue or goal signals: title, body, branch, ticket refs, and acceptance wording.
- Solution complexity is derived from the PR: files changed, churn, and implementation shape.
- CR cost is measured from Crosscheck logs: workflow minutes, review/fix minutes, and repeated review loops.
- Review-risk proxy comes from Crosscheck verdicts and fix loops. It is not production quality yet. We still need post-merge defect, incident, CI, revert, and follow-up-fix joins.
The scatterplot is useful precisely because it separates the demand from the implementation. If every solution were proportionate to the problem, the dots would hug a straight upward line: harder goals should usually require broader code. A fitted line over the observed PRs points in that direction, but only moderately (r = 0.52, R^2 = 0.27). In other words, problem complexity explains some solution size, but the solution can easily become more complex than the goal required.
The most important outliers are the simple-goal, complex-solution PRs above the fitted line:
| PR | Why it is an outlier | Likely cause |
|---|---|---|
| #233 blog system | Low goal score, very high solution score | A small stated goal hid a full subsystem: Astro blog, content model, assets, and deploy surface |
| #226 badge MVP | Trivial problem bucket, high-risk solution | Ten ticket refs were bundled into one PR, so the review story became much larger than the issue shape |
| #258 shared upload routing | Fix-shaped goal, broad implementation | ”Route uploads” crossed shared storage, campaign cover images, form assets, and data recording |
| #267 and #291 UI layering | Simple product-polish goals, broad UI changes | Visual refresh work tends to fan out across routes, state, assets, and layout conventions |
These are not necessarily bad PRs. They are warning labels. They usually come from under-specified goals, hidden platform work, bundled tickets, or a refactor/migration disguised as a small fix. The prevention pattern is simple: require a short implementation plan before large generated diffs, enrich issues with acceptance boundaries, split scaffolding from product behavior, and ask Crosscheck to flag PRs whose solution score is far above the fitted expectation for the goal.
This data can answer operating questions: which PR shapes are expensive, where review loops repeat, when stronger models are worth considering, and what Crosscheck should instrument next.
It cannot yet answer the final quality question by itself. Crosscheck verdicts are a useful review-risk proxy, but production code quality needs post-merge joins: reverts, follow-up fixes, CI failures, incident links, bug tickets, and customer-visible regressions.
Finding 1: make review routing proactive
The strongest product lesson is not “which telemetry field explains cost afterward.” The useful question is: which setup choices make a PR likely to need more review before we spend the review budget?
In this sample, ticket bundling was the clearest controllable cost signal. Problem complexity and solution complexity also mattered, but they describe different layers. The issue brings demand complexity. The coding agent creates one solution shape.
Crosscheck should route review strength from both.
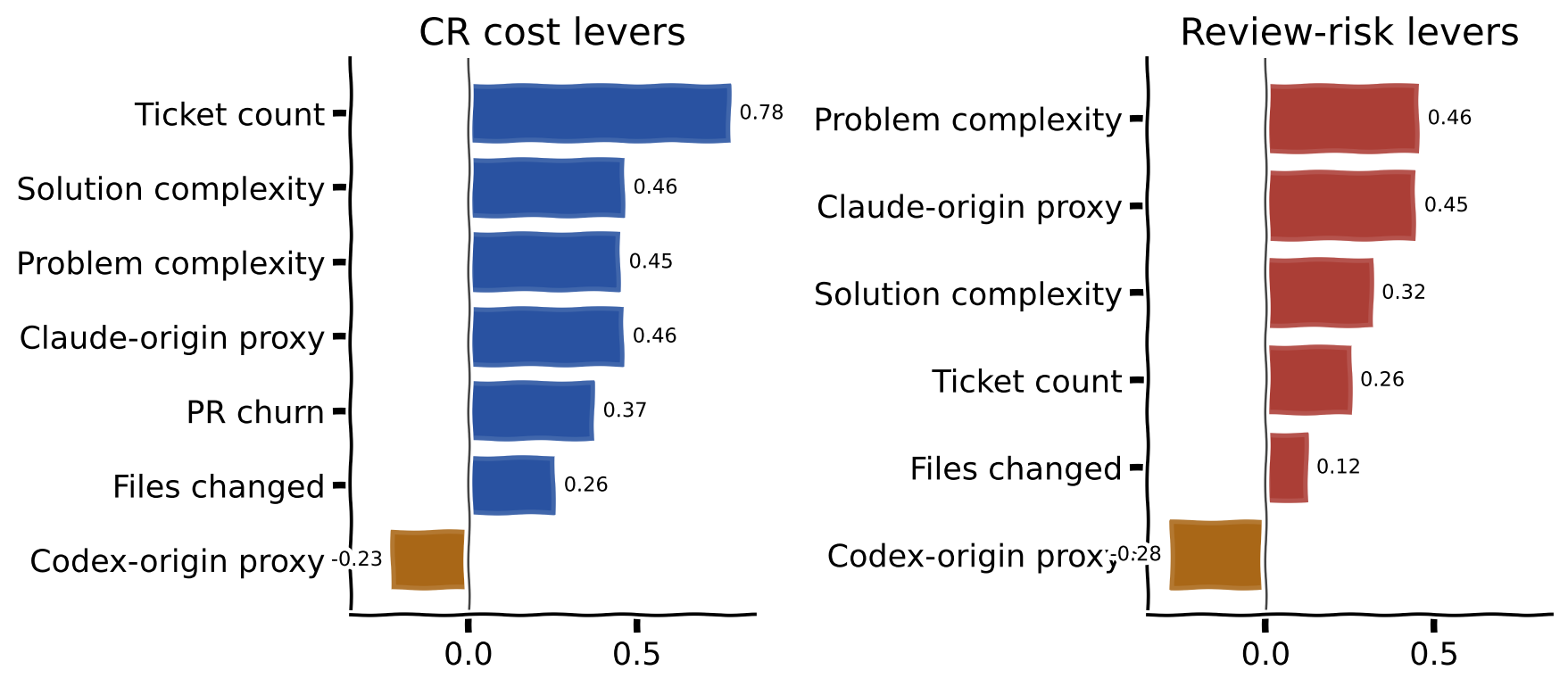
The routing inputs should be things a team can act on:
| Factor | What it tells us | Crosscheck action |
|---|---|---|
| Issue or goal complexity | How ambiguous or broad the demand is before code exists | Single-vendor review uses thorough for high ambiguity; cross-vendor review can stay balanced until risk signals appear |
| Ticket bundle size | Whether one PR is carrying one review story or several | Default to one ticket; allow 2-3 related tickets only in rush mode or one shared rollout; block or split 4+ tickets |
| PR solution shape | Whether the implementation is broad, risky, or cross-domain | If solution complexity is far above the fitted expectation, require an implementation-plan check and targeted tests |
| Coding agent and model provenance | Whether the original patch came from a known setup | Prefer cross-vendor review when the coding agent and reviewer would otherwise be the same setup |
| Workflow length and errors | Whether the run is becoming unstable | Stop after repeated errors, retry from a clean state, or hand off with context instead of extending the loop |
A practical router should classify the issue, estimate PR shape, capture coding-agent and model provenance, then choose a review lane:
- Single-ticket, single-domain PRs get fast review for turnaround.
- Cross-vendor review can use balanced mode as the default lane and should target roughly 30% better review throughput versus always-thorough review.
- Single-vendor review should escalate to thorough mode earlier, especially for ambiguous goals, auth, billing, storage, migrations, or data boundaries.
- Large bundles get explicit decomposition pressure before review starts.
- Domain-sensitive code gets human-plan or domain-owner gates.
Crosscheck already has workflow tiers such as balanced and thorough. The next product step is to make review strength an automatic routing decision, not a manual habit.
Finding 2: bundle related tickets, but stop before the PR becomes a program
The most practical process question is simple: should we ship a larger PR covering multiple tickets, or keep PRs small and run more review loops?
The default answer is one ticket per PR. It gives the fastest single-PR turnaround, keeps review context small, and makes approval easier to reason about.
The exception is rush mode. When the team needs highly parallel execution and the tickets are genuinely related, a 2-3 ticket bundle is worth trying. In the retained Crosscheck window, those PRs looked comparable to one-ticket PRs on median computer time and CR rounds, while preserving approve rate. That is a useful bundle size when the tickets form one coherent unit.
The stop sign is 4+ tickets. Those PRs became a different operating mode: higher median computer time, more review/fix time, more rounds, and a much lower approve rate. At that point, any theoretical throughput gain gets outrun by the prolonged code-review workflow required to reach APPROVE.
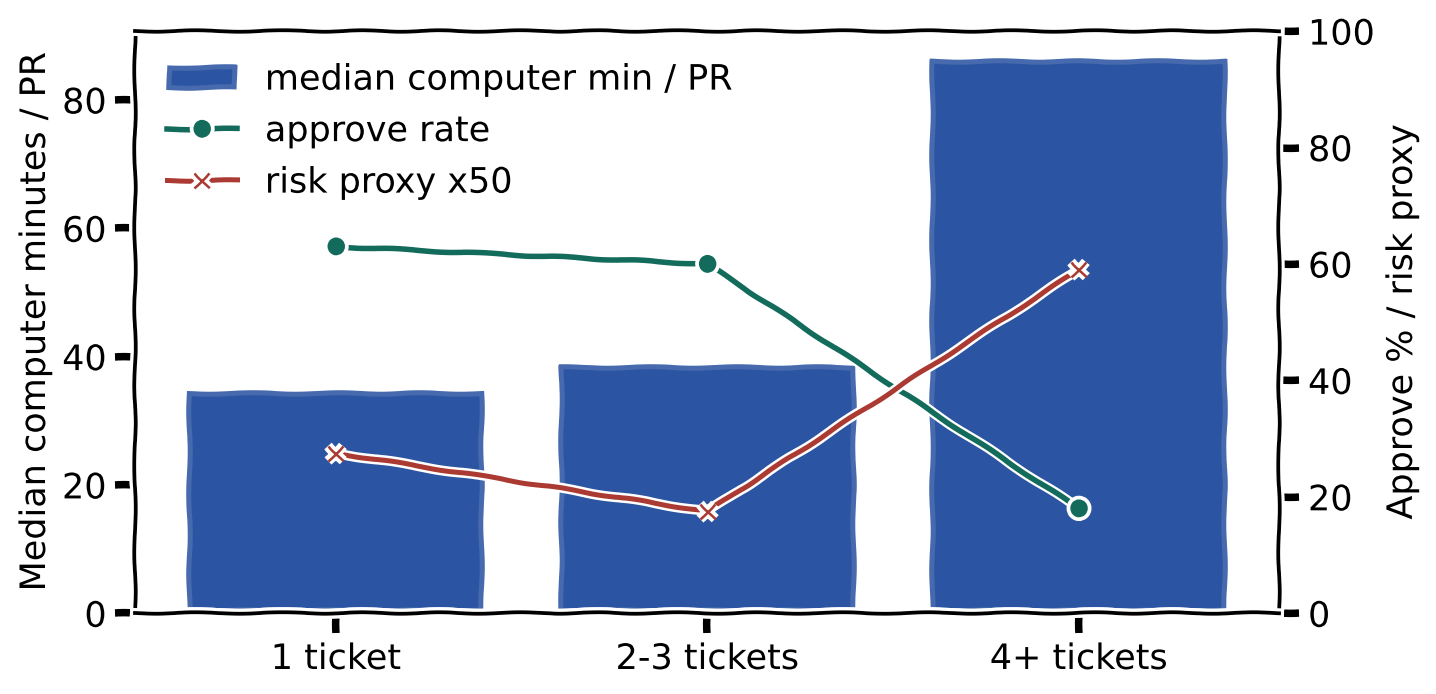
Median per-PR comparison:
| Bundle | Sample | Problem / solution | Workflow / PR | Review + fix / PR | CR rounds / PR | Wall-clock / PR | Approve |
|---|---|---|---|---|---|---|---|
| 1 ticket | 19 PRs / 19 tickets | 28.5 / 43.3 | 34.6m | 19.2m + 1.6m | 9 | 27.4h | 63% |
| 2-3 tickets | 10 PRs / 20 tickets | 32.3 / 43.5 | 38.7m | 11.6m + 1.1m | 9 | 57.1h | 60% |
| 4+ tickets | 11 PRs / 69 tickets | 52.6 / 82.0 | 86.4m | 46.5m + 10.7m | 13 | 41.5h | 18% |
The per-ticket view explains why bundling is tempting:
| Bundle | Avg workflow / PR | Tickets per review hour | Approve | Risk proxy |
|---|---|---|---|---|
| 1 ticket | 43.1m | 1.32 | 60% | 0.55 |
| 2-3 tickets | 38.8m | 2.81 | 55% | 0.36 |
| 4+ tickets | 124.1m | 3.03 | 18% | 1.18 |
The bad trade is visible only when cost and quality sit together. A 4+ ticket bundle can look efficient per ticket, but the approve rate collapses and the risk proxy more than doubles versus the 2-3 ticket bucket.
The operating rule we took from this:
Prefer one ticket when approval speed matters.
Bundle 2-3 tickets only when they are one evidence unit: same domain, same rollout, shared migration, or one acceptance flow.
Never treat 4+ tickets as a normal bundle. Split them before implementation, or require a human plan plus thorough cross-vendor review.
Finding 3: do not rank coding agents without provenance
The observed agent comparison is useful, but not fair enough to crown a winner.
Codex-origin PRs in this sample were mostly smaller site and product-polish changes. Claude-origin PRs carried more ticket refs, higher problem scores, and more backend/domain-risk work. The measured outcomes reflect task assignment as much as agent ability.
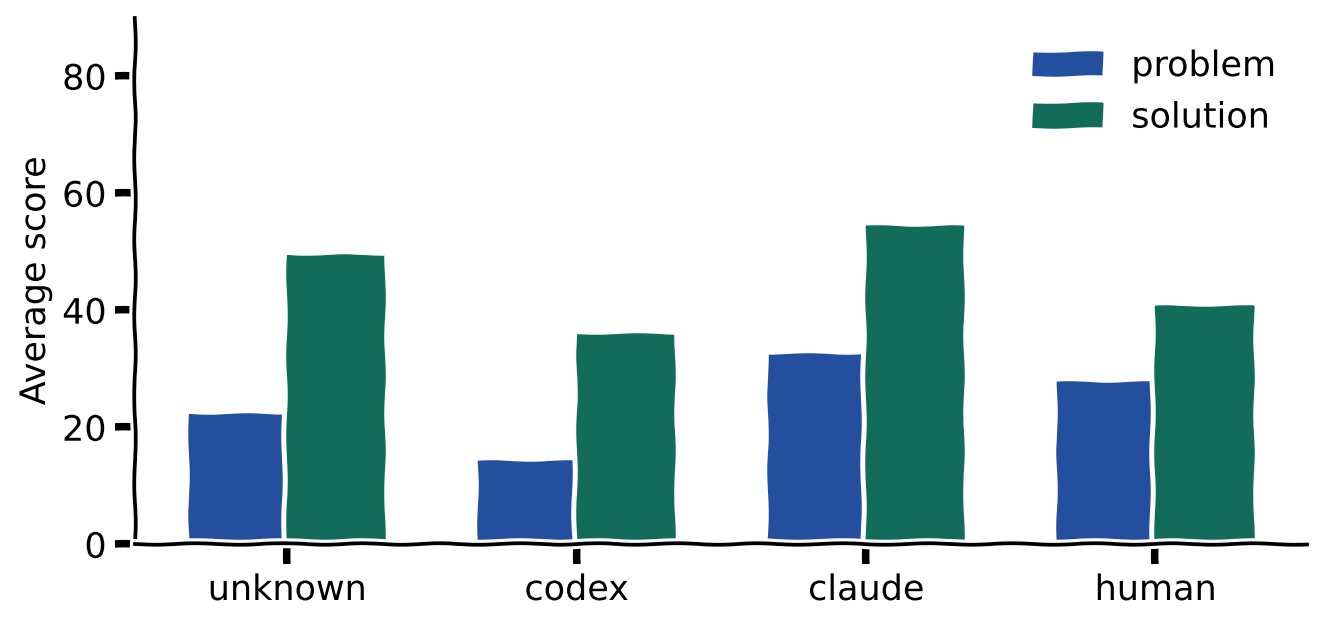
The origin proxy table shows the bias:
| Origin proxy | PRs | Ticket refs | Avg problem | Avg solution | Avg workflow | Avg rounds | Approve |
|---|---|---|---|---|---|---|---|
| Claude | 30 | 89 | 33.4 | 55.7 | 72.2m | 11.6 | 33% |
| Codex | 28 | 8 | 13.8 | 35.9 | 12.2m | 4.5 | 79% |
| Human | 11 | 11 | 27.8 | 40.7 | 37.2m | 8.7 | 82% |
| Unknown | 20 | 4 | 21.1 | 40.4 | 0.0m | 0.0 | 0% |
The conclusion is not “Codex is better” or “Claude is worse.” The conclusion is that Crosscheck needs first-class provenance for:
- original coding agent
- underlying model
- effort setting
- context strategy
- verification path
- original PR state versus Crosscheck-fixed state
Without that, task assignment bias overwhelms model choice.
What model comparison can tell us today
Reviewer model routing is more actionable than original coding-agent ranking because Crosscheck owns that part of the workflow.
In retained review-call logs, Claude Sonnet review calls were much faster than Claude Opus calls. Opus appeared on somewhat harder PRs, so this is not a quality ranking. It is a routing hint.
| Reviewer setup | Calls | PRs | Avg problem | Avg duration | Approve | Needs work | Block |
|---|---|---|---|---|---|---|---|
| Claude / Sonnet 4.6 | 61 | 30 | 17.0 | 63.2s | 62% | 36% | 2% |
| Claude / Opus 4.7 | 14 | 13 | 24.4 | 162.4s | 50% | 36% | 14% |
The practical policy: use smaller/faster models by default, then escalate to stronger models for high-risk PRs, reviewer disagreement, or repeated fix loops.
That gives Crosscheck a concrete routing policy:
| Lane | Good fit | Default reviewer setup | Escalation trigger |
|---|---|---|---|
| Fast | Small, single-domain, low ambiguity | Smaller/faster model, one pass | Any blocking finding, missing tests, or changed risk surface |
| Balanced | Normal feature or bugfix PR | Standard review plus targeted re-check | Repeated fix loop, broad diff, auth/data/migration code |
| Thorough | Complex goal, cross-domain PR, or 4+ ticket bundle | Stronger model and stricter review | Human plan check or domain-owner gate |
| Recovery | Failed, conflicted, or unstable workflow | Diagnose environment and state before more review | Stop looping and preserve context for handoff |
What this means for Crosscheck
Crosscheck does not need to magically make generated code good. Its leverage is more practical: make review reliable, observable, cheap enough to run often, and smart enough to spend effort where risk is highest.
The next product opportunities are clear:
- Issue-ticket enrichment. Join Linear/GitHub issue fields so problem complexity is measured from the goal, not inferred from the PR.
- Agent/model provenance. Record coding agent, model, effort, context strategy, and verification behavior for the original PR attempt.
- Complexity-aware workflow lanes. Route low-risk PRs through fast review, complex PRs through review plus targeted fix, and high-risk PRs through human-plan or domain-owner gates.
- Reliability preflight. Check GitHub auth, vendor CLI auth, repo access, and tunnel state before accepting PR work.
- Original vs. fixed state tracking. Separate original PR quality from Crosscheck-applied fix deltas.
- Real cost accounting. Persist provider, model, duration, retry count, and computed USD per reviewer/fixer call.
- Post-merge quality joins. Track reverts, follow-up fixes, bug issues, incidents, and CI failures after merge.
The product should turn these into defaults, not dashboards alone. A useful Crosscheck run should end with an answer like: “This PR is a good candidate for fast review”, “This PR is carrying three independent review stories”, or “This PR needs thorough review because the goal is high-ambiguity and the diff crosses data boundaries.”
The practice we want
AI-native engineering should not mean “let agents ship whatever they produce.” It should mean faster loops with better instrumentation.
Small goals should move quickly. Risky goals should get stronger gates. PRs should stay shaped for review. Models should be routed by expected risk, not habit. Every run should leave data behind so the workflow gets easier to improve.
For teams adopting agentic coding, the practice is not traditional review versus AI automation. It is traditional engineering discipline, made cheaper to run on every PR.
Crosscheck is our attempt to make that discipline operational: independent review, fix, re-check, conflict handling, cost visibility, and eventually quality feedback from production back into the next review.
That is how agentic teams can improve cadence and quality together.
Method notes
This is a retrospective of available data, not a controlled experiment. PR origin is inferred from titles, branches, and workflow artifacts. Ticket count is based on detected issue references, so unlinked work is undercounted. Wall-clock time is PR open to merge or close, so human scheduling and batching can dominate that metric.
The next analysis should join the issue tracker directly, record coding-agent and model provenance at PR creation time, and connect merged PRs to post-merge quality outcomes. That is the path from “review workflow telemetry” to a real model of code quality.
Try Crosscheck on GitHub at humanbased-ai/crosscheck, or install it from npm as @humanbased/crosscheck.